近年、社内文書、製品説明書、仕様書、社内規則といった多様なナレッジ資産を効率的に活用したいというニーズが高まっています。
特に、既存のUIを持たない企業でも迅速に導入可能な「ナレッジ参照AI」ツールの導入は、業務効率化や意思決定の迅速化に貢献すると期待されています。
本記事では、このニーズに応えるため、DifyとMicrosoft Azureの各種サービスを組み合わせ、RAG(Retrieval Augmented Generation)を介在させたAIチャットボットをプロトタイプとして構築した事例を紹介します。
なお、Dify自体もRAG機能を提供していますが、これは精度の面で商業利用には不十分であることがわかりました。
そのため、本プロジェクトではAzure AI Searchを中核としたRAGを採用し、より正確かつ信頼性の高いナレッジ検索を実現する構成としています。
このプロトタイプは、Webブラウザベースのチャットボットとして機能し、その実現可能性を検証することを目的としています。
目次
プロジェクトの概要と目的
本プロジェクトの主要な目的は、以下の通りです。
- ナレッジ参照AIツールの導入: 製品マニュアルや仕様書、社内規則などを効率的に検索・参照できるAIツールを構築する。
- 容易な導入と実現可能性の検証: UIが存在しない企業でも容易に導入できるよう、WebブラウザベースのAIチャットボットのプロトタイプを作成し、その実現可能性を検証する。
- DifyとAzureの活用: オープンソースのLLMアプリケーション開発プラットフォームであるDifyと、Microsoft Azureのサービス群を組み合わせて、簡易的なRAGを介在させたチャットツールを構築する。
技術スタックと主要なAzureコンポーネント
このRAGベースのナレッジ参照AIを構築するために、以下の技術スタックとAzureコンポーネントが活用されています。
- Dify:チャットボットのフロントエンドおよびアプリケーションレイヤーとして機能する。
- Azure OpenAI:本プロジェクトでは、GPT-4oモデルを利用した。
- Azure AI Search:RAGの中核をなす検索コンポーネント。ナレッジベースからの関連情報抽出を担う。
実装と検証の状況
以下の記事を参考に実装しました。 参考記事:https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/dify-work-with-microsoft-ai-search/4365255
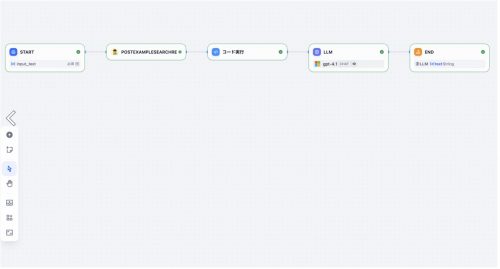
ワークフロー及び各ノードは以下の通りです。
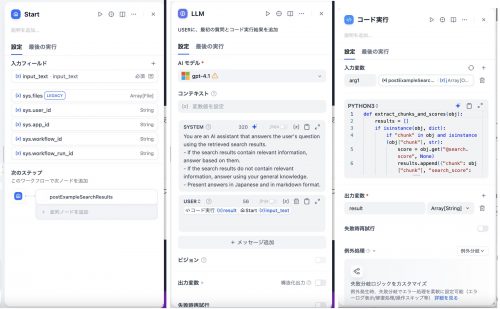
カスタムツールについては、以下のように設定しました。 なお、Search Service側の設定についてはこちらの記事(AzureだけでRAGを介在させたSlack Botを作る)を参照してください。
Authorization methodは、Header->Custom でkeyをapi-key 、valueはAI Searchの管理者キー とします。
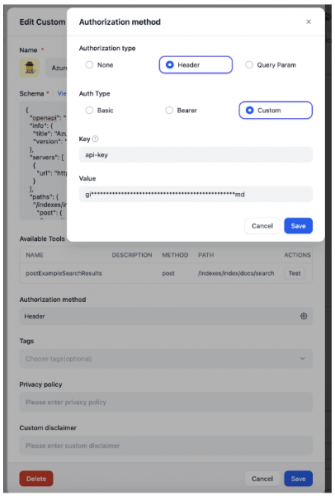
スキーマは以下のようにしました。
注意点として、RESTのリクエストをGETにすると膨大な量のトークンを出力するため、後段のLLMのContex Lengthを超えてしまい、エラーが出てしまうことが挙げられます。そのため、リクエストをPOSTにして出力を絞りました。
{
"openapi": "3.0.0",
"info": {
"title": "Azure Cognitive Search Integration",
"version": "1.0.0"
},
"servers": [
{
"url": "https://XXX-dev-eastus2.search.windows.net"
}
],
"paths": {
"/indexes/<インデックス名>/docs/search": {
"post": {
"operationId": "<カスタムツール名>",
"parameters": [
{
"name": "api-version",
"in": "query",
"required": true,
"schema": {
"type": "string",
"example": "2024-11-01-preview"
}
}
],
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/InputData"
}
}
}
},
"responses": {
"200": {
"description": "Successful response",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"@odata.context": { "type": "string" },
"value": {
"type": "array",
"items": {
"type": "object",
"properties": {
"@search.score": { "type": "number" },
"ID": { "type": "string" },
"Sample": { "type": "string" },
"Question": { "type": "string" },
"Answer": { "type": "string" },
"Category1": { "type": "string" },
"Category2": { "type": "string" },
"UM": { "type": "string" },
"ServiceMenu": { "type": "string" },
"AzureSearch_DocumentKey": { "type": "string" },
"metadata_storage_name": { "type": "string" },
"metadata_storage_path": { "type": "string" }
}
}
}
}
}
}
}
}
}
}
}
},
"components": {
"schemas": {
"InputData": {
"properties": {
"search": {
"type": "string",
"title": "Search"
},
"select": {
"type": "string",
"title": "Select"
},
"top": {
"type": "number",
"title": "Select"
}
},
"type": "object",
"required": [
"search",
"select"
],
"title": "InputData"
}
}
}
}
カスタムツールはJSON形式で出力を行いますが、今回LLMノードに渡したい部分であるナレッジの内容はJSON内のネストが深すぎる場所にあり、直接LLMノードに渡すことができないという問題が発生しました。
そのため、資料の内容をテキスト化するPythonコード実行することで、LLMノードに渡すことができる形に直しました。
コード実行ノードに記載したPythonコードは以下の通りです。(このコードの場合、コード実行ノードに例外分岐をつけ、終了ノードに繋げる必要があります。)
def extract_chunks_and_scores(obj):
results = []
if isinstance(obj, dict):
if "chunk" in obj and isinstance(obj["chunk"], str):
score = obj.get("@search.score", None)
results.append({"chunk": obj["chunk"], "search_score": score})
for k, v in obj.items():
if k != "chunk":
results.extend(extract_chunks_and_scores(v))
elif isinstance(obj, list):
for item in obj:
results.extend(extract_chunks_and_scores(item))
return results
def main(arg1) -> dict:
try:
data = arg1
extracted = extract_chunks_and_scores(data)
result_list = [item["chunk"] for item in extracted if item["search_score"] is not None and item["search_score"] >= 6]
return {"result": result_list}
except Exception as e:
return {"result": [f"Error: {str(e)}"]}
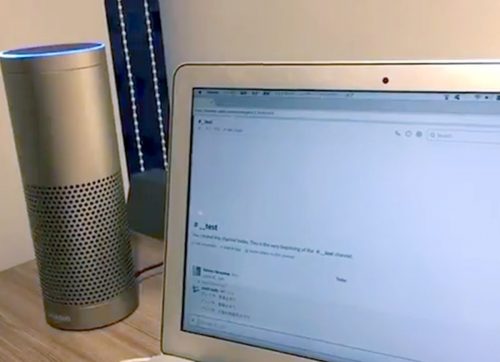
これにより、以下のようにRAGにより社内情報を参照した回答を得られるようになりました。
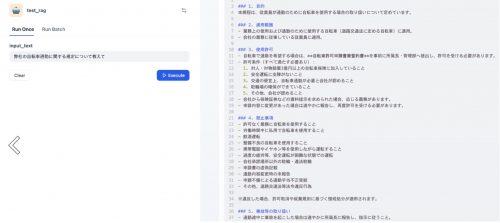
本プロトタイプを通じて、Azureの強力なRAG基盤とDifyの柔軟なアプリケーションフレームワークを組み合わせることで、企業内のナレッジをより正確かつ効率的に活用できる手応えを得ることができました。
今後は実運用での検証やさらなる最適化を進め、業務現場で確実に役立つナレッジ参照AIへと発展させていきたいと考えています。