Slack Bot に社内ナレッジの自動応答(RAG)を組み込む構想は以前から進めていて、すでに Node.js 製のエージェントをベースとした実装も存在していました。 [Azure OpenAIでRAGを構築してチャットボットを作ってみた【part1】]
しかし、この構成ではRAG(Retrieval-Augmented Generation)による出力のみに依存していたため、一般的な返答(たとえば雑談やテンプレ応答)との切り分けが難しく、Botの応答制御に限界を感じていました。
そこで、以下のような目的で今回のBotを新たに構築し直すことにしました:
通常の出力とRAGベースの出力を明確に切り分ける構造にしたい
Node.jsからPythonへの技術スタックの移行を進めたい
Azureのリソースのみを活用したSlack Bot構成を再設計する
最終的に、ナレッジを検索して回答できるRAG構成と、通常のやりとりにも対応できる柔軟なSlack Botが完成しました。
Bot FrameWork SDKでEcho Botが動作できている前提です。
目次
概要図
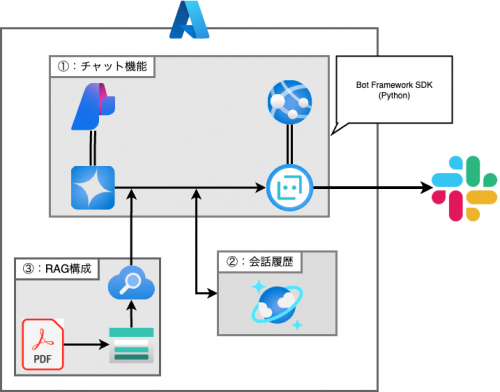
1. 必要なリソース関係
※デプロイしたモデル名やAPIキー、エンドポイント等はこの後のプログラムやSearch Skillset連携時にも利用します。
Azure Cosmos DB の作成(会話履歴の保存用)
Botでの会話履歴を保存・取得するために、Azure Cosmos DB(NoSQL API) を利用します。
Azureポータルから Cosmos DB アカウントを作成し、適当なデータベースとコンテナーを用意します。
コンテナーには、ユーザーの発言やAIの応答などの会話ログを記録しておき、次の応答時に参照します。
userID などをパーティションキーとして設定することで、ユーザー単位の履歴管理が可能です。
Azure OpenAIでモデルのデプロイ
RAGで検索対象データの埋め込み(ベクトル化)や生成AIを使った回答処理を行うために、まずAzure OpenAI Serviceで推論モデルをデプロイします。
ここでは、例えば "text-embedding-3-small" など、埋め込み用(embedding)モデルのデプロイが必要になります。
- Azureポータルで「Azure OpenAI Service」を検索し、サービスの作成画面へ進みます。
- サービスが作成できたら、リソースグループ や リージョンなどを選択します。
- 「モデル管理」から利用できるモデル(例:text-embedding-3-small等)を選択し、カスタム名を付けてデプロイします。
本投稿では、text-embedding-3-smallを利用する前提で話を進めていきます。
ストレージ アカウントの作成(RAG用)
RAG構成では、検索対象となるPDFファイルや文書データを格納する「Azure Storage」が必要です。
- Azureポータルの検索バーで「ストレージ アカウント」と検索します。
- 「+作成」から新たなストレージアカウントを作成します。
- リソースグループ、アカウント名、リージョン等を設定
- 作成後、「コンテナー」(Blobコンテナー)を作成し、ここに対象文書(PDFやテキスト等)をアップロードしていきます。
※このストレージが後ほど、Search Serviceの データソース 及びインデクサーのクロール対象になります。
Azure Search Service
Azure Search Service(旧Cognitive Search)は、ドキュメントの全文検索やベクトル検索の基盤です。 主に以下の3つを設定していきます。
- インデックス
- 検索対象となるフィールド(例:
chunk,text_vector,title,urlなど)を定義します。
- 検索対象となるフィールド(例:
- インデクサー
- 設定したBlobストレージやデータソースからドキュメントを自動でクロールし、インデックスへ投入します。
- スキルセット
- ドキュメント分割(SplitSkill)やベクトル生成(AzureOpenAIEmbeddingSkill)などRAG向けの自動前処理パイプラインを構成します。
- 例として、2000文字ごと500文字オーバーラップで分割し、各チャンク単位でembeddingを生成するといった設定が可能です。
1. インデックスを作成
- Search Service のメニューから「インデックス」を選択し、「+追加」ボタンをクリック。
- ドキュメントごと(例: chunk, text_vector, title, url など)のフィールド名・型を指定して作成します。
2. スキルセットを作成
- 「スキルセット」を選択し、「+追加」で新規スキルセットを作成。
- ドキュメント分割(SplitSkill)、ベクトル生成(AzureOpenAIEmbeddingSkill)など必要なスキルを構成します。
- 必要に応じてAPIキーやOpenAIリソース参照情報などを入力。
スキルセットのサンプル(JSON)
{
"name": "my-skillset",
"description": "Skillset to chunk documents and generate embeddings",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": "Split skill to chunk documents",
"context": "/document",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0,
"unit": "characters",
"inputs": [
{ "name": "text", "source": "/document/content" }
],
"outputs": [
{ "name": "textItems", "targetName": "pages" }
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "#2",
"context": "/document/pages/*",
"resourceUri": "---",
"apiKey": "<redacted>",
"deploymentId": "text-embedding-3-small",
"dimensions": 1536,
"modelName": "text-embedding-3-small",
"inputs": [
{ "name": "text", "source": "/document/pages/*" }
],
"outputs": [
{ "name": "embedding", "targetName": "text_vector" }
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "index",
"parentKeyFieldName": "parent_id",
"sourceContext": "/document/pages/*",
"mappings": [
{ "name": "text_vector", "source": "/document/pages/*/text_vector" },
{ "name": "chunk", "source": "/document/pages/*" },
{ "name": "title", "source": "/document/title" },
{ "name": "url", "source": "/document/url" }
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
}
}
3. インデクサーを作成・接続
- 「インデクサー」を選択し、「+追加」で新規インデクサーを作成します。
- データソース(例: Blobストレージ)を選択します。
- 「ターゲットインデックス」で先ほど作成したインデックスを選択します。
- 「スキルセット」で、作成済みのスキルセットを指定することで「ストレージ→スキルセット(前処理)→インデックス」ルートが自動的に連携されます。
すべてを紐づけて保存・実行すると、Blobストレージ内のドキュメントが指定どおりのチャンク・ベクトル化処理を経て、インデックスに蓄積されます。
2.RAGの構築プログラム
会話履歴を参照できて、かつRAGを参照できるプログラムの完成形が以下のようになっています。
ディレクトリ構造
echo_bot/ │ ├── __pycache__/ │ ├── deploymentTemplates/ │ ├── .env.sample ├── .pylintrc ├── README.md ├── __init__.py ├── app.py ├── bot.py ├── config.py ├── openai_service.py ├── requirements.txt ├── startup.sh
openai_service.py
# Azure OpenAIに繋げる import os from openai import AzureOpenAI from dotenv import load_dotenv import traceback # RAG処理できるようにAzure Searchとも繋げる from azure.search.documents import SearchClient from azure.core.credentials import AzureKeyCredential # 会話履歴を参照するため、CosmosDBとも繋げる from azure.cosmos import CosmosClient from azure.identity import DefaultAzureCredential #id生成用 import uuid #mrkdwnに変換するためのライブラリをインストール from markdown_to_mrkdwn import SlackMarkdownConverter load_dotenv() # Azure OpenAIに接続するためのクライアント作成 client = AzureOpenAI( api_key=os.getenv("AZURE_OPENAI_API_KEY"), api_version=os.getenv("AZURE_OPENAI_API_VERSION"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), ) # Azure Searchに接続するためのクライアント作成 search_client = SearchClient( endpoint=os.getenv("AZURE_SEARCH_ENDPOINT"), index_name=os.getenv("AZURE_SEARCH_INDEX_NAME"), credential=AzureKeyCredential(os.getenv("AZURE_SEARCH_KEY")) ) # Cosmos DBに接続するためのクライアント作成 credential = DefaultAzureCredential() cosmos_client = CosmosClient( url=os.getenv("AZURE_COSMOS_ENDPOINT"), credential=os.getenv("AZURE_COSMOS_KEY") ) # DB名、コンテナ名を取得 database = cosmos_client.get_database_client(os.getenv("AZURE_COSMOS_DB_NAME")) container = database.get_container_client(os.getenv("AZURE_COSMOS_CONTAINER_NAME")) #mrkdwnへのコンバーターを作成 converter = SlackMarkdownConverter() #RAGかどうかの確認・対象によって変更すること。 storageAccountURL="blobコンテナを参照" # ドキュメント検索(与えられた質問(query)をもとに検索) def search_documents(query: str) -> str: # 質問をAzure Searchに投げて検索 results = search_client.search(query) docs = [] # 一件ずつ取り出す for result in results: chunk = result["chunk"] url = result["url"] if url: docs.append(f"{chunk}\n【出典】{url}") else: docs.append(chunk) return "\n\n".join(docs) #CosmosDBから直近10件の会話履歴を取得 def get_conversation_history(user_id: str, limit: int =10): query = f"SELECT TOP {limit} * FROM c WHERE c.userID = @userID ORDER BY c._ts DESC" items = list(container.query_items( query=query, parameters=[ { "name": "@userID", "value": user_id } ], enable_cross_partition_query=True ) ) items.reverse() return items async def chat_with_openai(user_input: str, user_id: str) -> str: try: #会話履歴の取得 history = get_conversation_history(user_id) context = search_documents(user_input) prompt = f""" 任意のプロンプト <社内文書一覧> {context} (RAGによる文書データ一覧をプロンプト内に入れる) """ # システムメッセージを入れる messages = [{"role": "system", "content": prompt}] #会話履歴を追加 for item in history: messages.append({ "role": "user", "content": item["req"] }) messages.append({ "role": "assistant", "content": item["res"] }) # ユーザーからの質問を追加 messages.append({ "role": "user", "content": user_input }) # Azure OpenAIにリクエストを送る response = client.chat.completions.create( model=os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME"), messages=messages ) #回答部分を抽出 reply = response.choices[0].message.content #解答をmrkdown形式に整形 formatted_reply = converter.convert(reply) # CosmosDBにデータを追加する container.upsert_item({ "req": user_input, # ユーザーからの質問 "res": reply, # それに対するAIの回答 "userID": user_id, "conversationId": user_id, "id": str(uuid.uuid4()) # idを自動生成 }) return formatted_reply except Exception as e: traceback.print_exc() return f"エラー: {e}"
config.py
ここで利用されている各種変数名は、各々の環境に合わせて変更するようにしてください。
#!/usr/bin/env python3 # Copyright (c) Microsoft Corporation. All rights reserved. # Licensed under the MIT License. import os class DefaultConfig: """ Bot Configuration """ PORT = 3978 APP_ID = os.environ.get("MicrosoftAppId", "") APP_PASSWORD = os.environ.get("MicrosoftAppPassword", "") APP_TYPE = os.environ.get("MicrosoftAppType", "") AZURE_OPENAI_API_KEY=os.environ.get("AZURE_OPENAI_API_KEY", "") AZURE_OPENAI_ENDPOINT=os.environ.get("AZURE_OPENAI_ENDPOINT", "") AZURE_OPENAI_DEPLOYMENT_NAME=os.environ.get("AZURE_OPENAI_DEPLOYMENT_NAME", "") AZURE_OPENAI_API_VERSION=os.environ.get("AZURE_OPENAI_API_VERSION", "") AZURE_SEARCH_ENDPOINT=os.environ.get("AZURE_SEARCH_ENDPOINT", "") AZURE_SEARCH_KEY=os.environ.get("AZURE_SEARCH_KEY", "") AZURE_SEARCH_INDEX_NAME=os.environ.get("AZURE_SEARCH_INDEX_NAME", "") AZURE_COSMOS_ENDPOINT=os.environ.get("AZURE_COSMOS_ENDPOINT", "") AZURE_COSMOS_KEY=os.environ.get("AZURE_COSMOS_KEY", "") AZURE_COSMOS_DB_NAME=os.environ.get("AZURE_COSMOS_DB_NAME", "") AZURE_COSMOS_CONTAINER_NAME=os.environ.get("AZURE_COSMOS_CONTAINER_NAME", "")
requirements.txt
versionは、2025/08/04時点での作業環境のため、更新があるかもしれませんので、留意下さい。
aiohappyeyeballs==2.6.1 aiohttp==3.11.18 aiosignal==1.3.2 annotated-types==0.7.0 anyio==4.9.0 arrow==1.3.0 async-timeout==5.0.1 asyncio==3.4.3 attrs==25.3.0 azure-common==1.1.28 azure-core==1.34.0 azure-cosmos==4.9.0 azure-search-documents==11.5.2 binaryornot==0.4.4 botbuilder-core==4.16.2 botbuilder-schema==4.16.2 botframework-connector==4.16.2 botframework-streaming==4.16.2 certifi==2025.4.26 cffi==1.17.1 chardet==5.2.0 charset-normalizer==3.4.2 click==8.1.8 cookiecutter==1.7.0 cryptography==45.0.2 distro==1.9.0 exceptiongroup==1.3.0 frozenlist==1.6.0 future==1.0.0 h11==0.16.0 httpcore==1.0.9 httpx==0.28.1 idna==3.10 isodate==0.7.2 Jinja2==3.1.6 jinja2-time==0.2.0 jiter==0.10.0 jsonpickle==1.4.2 MarkupSafe==3.0.2 msal==1.32.3 msrest==0.7.1 multidict==6.4.4 oauthlib==3.2.2 openai==1.81.0 poyo==0.5.0 propcache==0.3.1 pycparser==2.22 pydantic==2.11.4 pydantic_core==2.33.2 PyJWT==2.10.1 python-dateutil==2.9.0.post0 python-dotenv==1.1.0 requests==2.32.3 requests-oauthlib==2.0.0 six==1.17.0 sniffio==1.3.1 tqdm==4.67.1 types-python-dateutil==2.9.0.20250516 typing-inspection==0.4.1 typing_extensions==4.13.2 urllib3==2.4.0 whichcraft==0.6.1 yarl==1.20.0
3.終わりに
以上、Azureのリソースを活用してSlack BotにRAGを組み込む手順をご紹介しました。 基本の構成から、実装、リソース設計までざっくり掴めたのではないかと思います。 今後、プロンプト設計やユーザー体験の最適化を進める際のベースにもなるはずです。 少しでも参考になれば幸いです!
参考
- Azure AI Search のスキルセット設定ガイド(Microsoft公式Docs)
- Azure インデクサーとスキルセットの連携イメージとFAQ(Microsoft公式Docs)
- Azure OpenAI Embedding Skill の使い方(クラウドネイティブブログ)
- Azure Blob ストレージとSearch Service連携手順(公式)