AstraDBはクラウド型NoSQLデータベースで、ベクトル検索やRAGなど最新のAI活用にも適しています。
今回は、AstraDBに、Pythonを使って接続し、データを挿入してみた体験を共有します。
開発環境
・言語 Python 3.13.3
・仮想環境 venv
AstraDBのセットアップ
AstraDBを開き、Quick Access -> Create a Databaseを選択し、データベースを作成します。
今回はデータベースをこのように指定しました:
・Provider: Amazon Web Services
・Region: us-east-2
データベースが作成できたら次はPython側へ移ります
PythonでAstraDBのコレクションの作成
Pythonでの環境構築を行います。 ターミナル上で以下のコードを実行します。
python3 -m venv venv source venv/bin/activate #仮想環境の起動 pip install astrapy #astradbのPython SDK pip install dotenv #.envからの認証情報の取得
.envファイルを作成し、AstraDBと接続するための認証情報を保存します。
ASTRA_DB_API_ENDPOINT=APIエンドポイント ASTRA_DB_APPLICATION_TOKEN=発行したトークン
それでは実際に動かすコードを作成します。
今回は、test_collectionというコレクションを作成してみます。
名前はastra_create.pyとしました。
import os
from astrapy import DataAPIClient, Database
from astrapy.constants import VectorMetric
from astrapy.info import (
CollectionDefinition,
CollectionVectorOptions,
VectorServiceOptions,
)
from dotenv import load_dotenv
load_dotenv()
def connect_to_database() -> Database:
endpoint = os.environ.get("ASTRA_DB_API_ENDPOINT")
token = os.environ.get("ASTRA_DB_APPLICATION_TOKEN")
if not token or not endpoint:
raise RuntimeError(
"Environment variables ASTRA_DB_API_ENDPOINT and ASTRA_DB_APPLICATION_TOKEN must be defined"
)
client = DataAPIClient()
database = client.get_database(endpoint, token=token)
print(f"Connected to database {database.info().name}")
return database
def create_collection() -> None:
database = connect_to_database()
# コレクションを作成
collection = database.create_collection(
"test_collection", #コレクション名
definition=CollectionDefinition(
vector=CollectionVectorOptions(
metric=VectorMetric.COSINE,
service=VectorServiceOptions(
provider="nvidia",
model_name="NV-Embed-QA",
),
)
),
)
print(f"Created collection {collection.full_name}")
if __name__ == "__main__":
create_collection()
実行結果
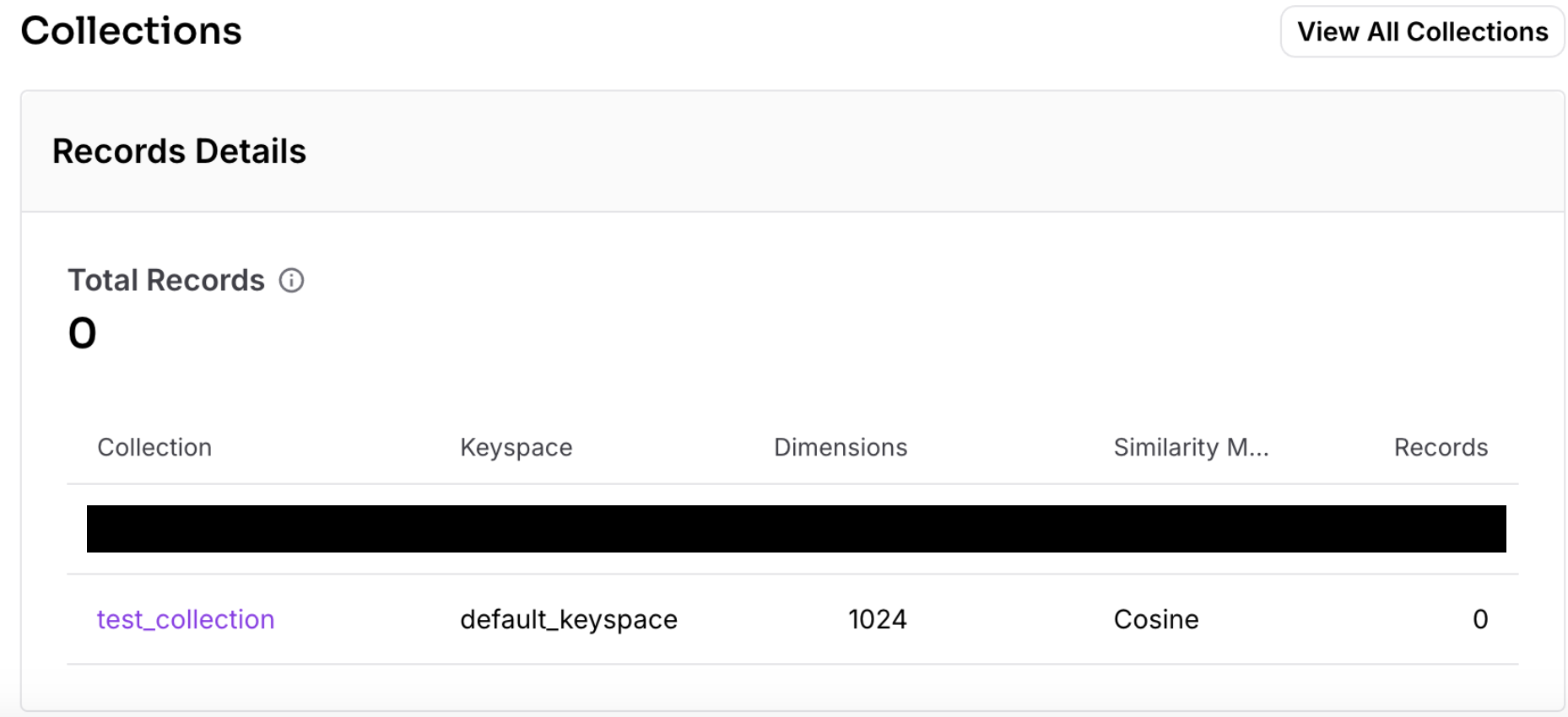
指定したコレクション名あるtest_collectionというコレクションが作成できました。
PythonからAstraDBへのデータの挿入
PythonからAstraDBへはJSONファイルを用いてデータの挿入を行います。
今回は例としてこのようなtest_dataset.jsonを作成しました。
[
{
"shop_name": "ラーメンA",
"location": "東京都渋谷区",
"rating": 4.5,
"review": "スープが濃厚で、チャーシューはとろけるような美味しさ。行列ができるのも納得。",
"tags": ["濃厚豚骨", "チャーシュー", "行列店"],
"visit_date": "2024-11-20",
"$vectorize": "review: スープが濃厚で、チャーシューはとろけるような美味しさ。行列ができるのも納得。 | tags: 濃厚豚骨, チャーシュー, 行列店"
},
{
"shop_name": "ラーメンB",
"location": "大阪府梅田",
"rating": 3.8,
"review": "醤油ベースのスープはあっさりしていて飲みやすい。女性客にも人気。",
"tags": ["あっさり醤油", "女性に人気"],
"visit_date": "2024-10-15",
"$vectorize": "review: 醤油ベースのスープはあっさりしていて飲みやすい。女性客にも人気。 | tags: あっさり醤油, 女性に人気"
},
{
"shop_name": "ラーメンC",
"location": "北海道札幌市",
"rating": 4.2,
"review": "味噌ラーメンの本場だけあって、スープに深みがあり、野菜の甘さも引き立つ。",
"tags": ["味噌ラーメン", "札幌", "野菜たっぷり"],
"visit_date": "2024-12-05",
"$vectorize": "review: 味噌ラーメンの本場だけあって、スープに深みがあり、野菜の甘さも引き立つ。 | tags: 味噌ラーメン, 札幌, 野菜たっぷり"
},
{
"shop_name": "ラーメンD",
"location": "福岡県博多市",
"rating": 4.9,
"review": "細麺と豚骨スープのバランスが絶妙で、替え玉を何度もしたくなる中毒性あり。",
"tags": ["博多", "細麺", "豚骨"],
"visit_date": "2024-12-10",
"$vectorize": "review: 細麺と豚骨スープのバランスが絶妙で、替え玉を何度もしたくなる中毒性あり。 | tags: 博多, 細麺, 豚骨"
},
{
"shop_name": "ラーメンE",
"location": "京都府京都市",
"rating": 3.5,
"review": "観光地のど真ん中にありアクセス抜群。味は無難だが観光ついでに寄るには良い。",
"tags": ["観光地", "アクセス良好", "万人向け"],
"visit_date": "2024-09-30",
"$vectorize": "review: 観光地のど真ん中にありアクセス抜群。味は無難だが観光ついでに寄るには良い。 | tags: 観光地, アクセス良好, 万人向け"
}
]
この作成したデータをAstraDBに挿入していきます。
import os
import json
from dotenv import load_dotenv
from astrapy.data_types import DataAPIDate
from astrapy import DataAPIClient
from astra_create import connect_to_database #astra_create: コレクションを作成するスクリプト
# .env ファイルを読み込む
load_dotenv()
db = connect_to_database()
collection = db.get_collection("test_collection") #コレクション名の指定
# JSONファイルを読み込み
with open("test_dataset.json", "r", encoding="utf8") as file:
json_data = json.load(file)
# ドキュメント整形
documents = [
{
**data,
"visit_date": (
DataAPIDate.from_string(data["visit_date"]) if data.get("visit_date") else None
),
"$vectorize": f"review: {data['review']} | tags: {', '.join(data['tags'])}",
}
for data in json_data
]
# 挿入
inserted = collection.insert_many(documents)
print(f"Inserted {len(inserted.inserted_ids)} documents.")
print(f"Inserted IDs: {inserted.inserted_ids}")
実行結果
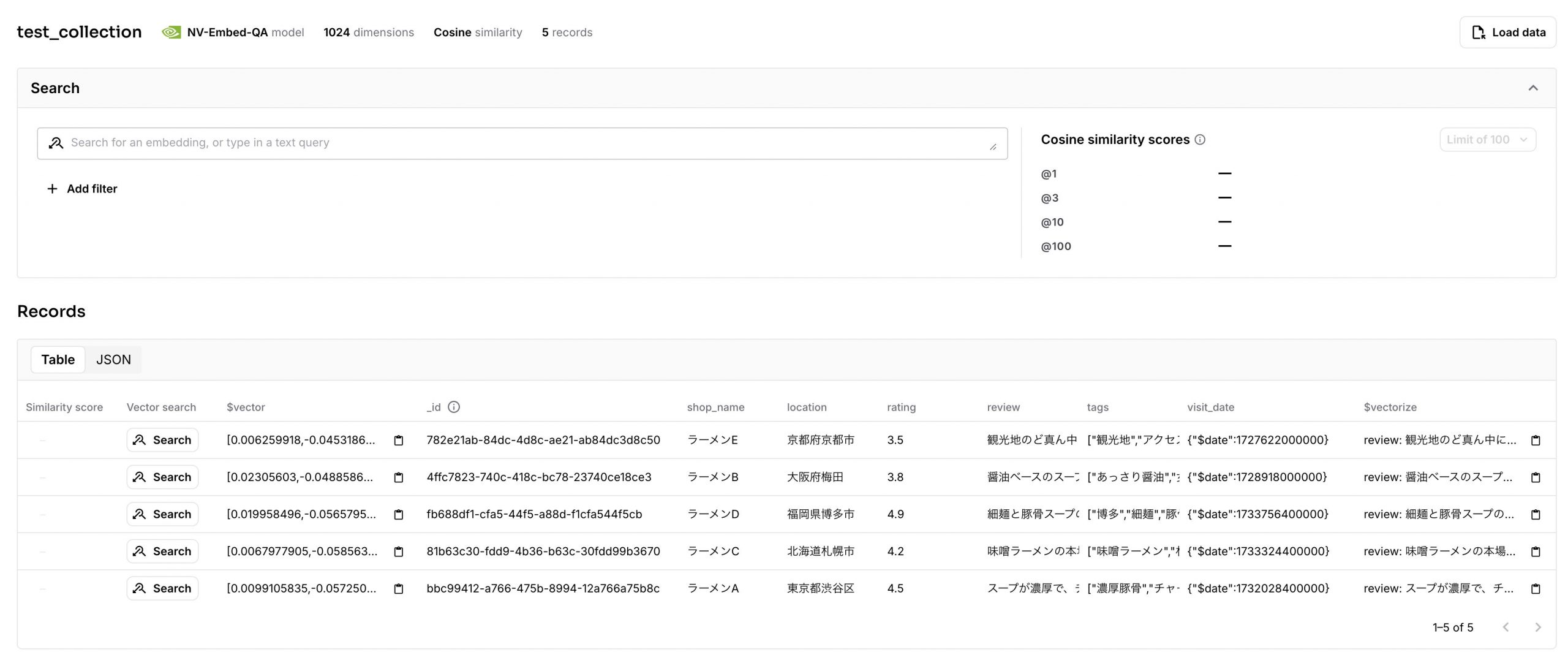
AstraDBにJSONファイルのデータが挿入されたことが確認できました。
まとめ
Pythonを使って、AstraDBにデータを挿入することができました。
今後はこのデータを使ってデータの検索にもチャレンジしてみたいです。