こんにちは。hacknoteのr.katoです。
前回、Deep Learning AMIを使ってみた(失敗)でt2.microを使ってみたところ
source activateの時にメモリ不足やCPUクレジット不足が原因でうまくいかなかったので、今回は推奨環境のc4.largeを使ってmnistをしました。
やったこと
推奨環境(CPU)でDeep Learning AMI(DLAMI)を使ってkerasサンプルコードのmnistを実行する。
インスタンス情報
- c4.large
- Deep Learning AMI (Ubuntu 18.04) Version 26.0 ami-07729b5941107618c
- python 3.6.5 anaconda
- tensorflow 2.0.0
- keras 2.3.0
- ボリュームタイプ standard 100GB
実際に実行したサンプルコード
下記のkerasが提供しているサンプルコードに実行時間を出力するコードを加えたものを実行しました。
https://github.com/keras-team/keras/blob/master/examples/mnist_cnn.py
実際の様子
login
前回の記事で紹介しましたが、sshでログインした際には、次の画像のようにDLAMIのAnacondaに設定してある仮想環境のリストと、その環境のacvtivateのコマンドが表示されるのでかなり楽です。
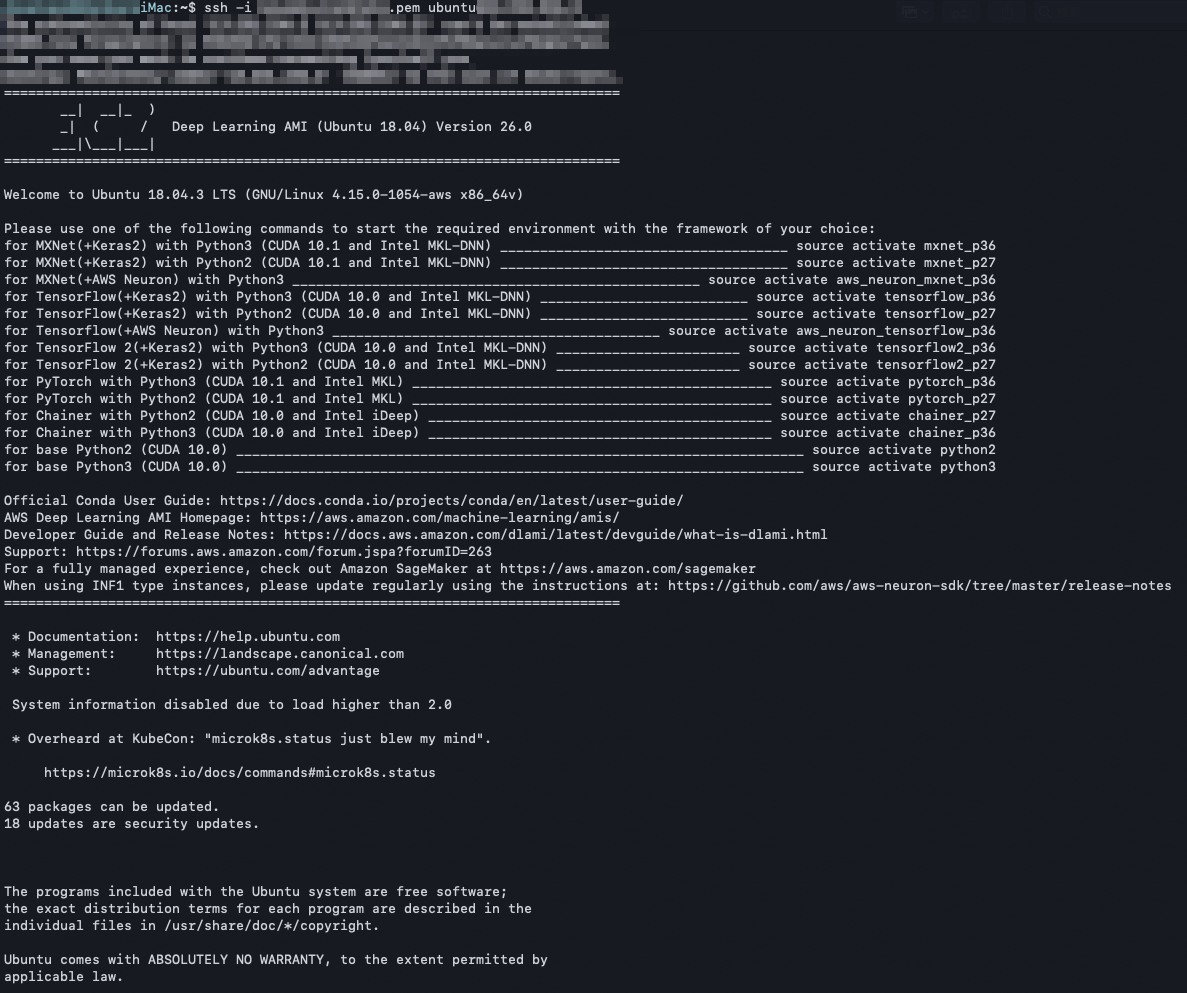
Anacondaの仮想環境をactivateする
今回はtensorflow2がバックエンドで動くkeras2の環境を使いたかったので、
source activate tensorflow2_p36 を実行しました。
体感だと3分程度ですんなりとactivateされました。
その時の出力も貼っておきます。
ただちょっと長いので折りたたんでおきますので気になる方はクリックしてください。
ubuntu@ip-xxx-xx-xx-xx:~$ source activate tensorflow2_p36 WARNING: First activation might take some time (1+ min). Installing TensorFlow optimized for your Amazon EC2 instance...... Env where framework will be re-installed: tensorflow2_p36 Instance c4.large is identified as a CPU instance, uninstalling tensorflow-gpu, installing optimized version of the Deep Learning framework. Installing Tensorflow optimized for your Amazon EC2 instance...... Env where framework will be re-installed: tensorflow2_p36 WARNING: First activation might take some time (1+ min). Uninstalling tensorflow-gpu-2.0.0: Successfully uninstalled tensorflow-gpu-2.0.0 Processing ./.dl_binaries/tensorflow2/cpu_3.6/tensorflow-2.0.0-cp36-cp36m-manylinux2010_x86_64.whl Requirement already satisfied: google-pasta>=0.1.6 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.1.8) Requirement already satisfied: keras-applications>=1.0.8 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.0.8) Requirement already satisfied: tensorflow-estimator<2.1.0,>=2.0.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (2.0.1) Requirement already satisfied: termcolor>=1.1.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.1.0) Requirement already satisfied: wheel>=0.26 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.33.6) Requirement already satisfied: wrapt>=1.11.1 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.11.2) Requirement already satisfied: gast==0.2.2 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.2.2) Requirement already satisfied: absl-py>=0.7.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.8.1) Requirement already satisfied: opt-einsum>=2.3.2 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (3.1.0) Requirement already satisfied: keras-preprocessing>=1.0.5 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.1.0) Requirement already satisfied: grpcio>=1.8.6 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.25.0) Requirement already satisfied: astor>=0.6.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.8.0) Requirement already satisfied: tensorboard<2.1.0,>=2.0.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (2.0.1) Requirement already satisfied: numpy<2.0,>=1.16.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.17.4) Requirement already satisfied: protobuf>=3.6.1 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (3.10.0) Requirement already satisfied: six>=1.10.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.13.0) Requirement already satisfied: h5py in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from keras-applications>=1.0.8->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (2.10.0) Requirement already satisfied: google-auth<2,>=1.6.3 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.7.1) Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.4.1) Requirement already satisfied: werkzeug>=0.11.15 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.16.0) Requirement already satisfied: setuptools>=41.0.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (41.6.0) Requirement already satisfied: markdown>=2.6.8 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (3.1.1) Requirement already satisfied: cachetools<3.2,>=2.0.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from google-auth<2,>=1.6.3->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (3.1.1) Requirement already satisfied: pyasn1-modules>=0.2.1 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from google-auth<2,>=1.6.3->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.2.7) Requirement already satisfied: rsa<4.1,>=3.1.4 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from google-auth<2,>=1.6.3->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (4.0) Requirement already satisfied: requests-oauthlib>=0.7.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.3.0) Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from pyasn1-modules>=0.2.1->google-auth<2,>=1.6.3->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (0.4.8) Requirement already satisfied: requests>=2.0.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (2.20.0) Requirement already satisfied: oauthlib>=3.0.0 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (3.1.0) Requirement already satisfied: chardet<3.1.0,>=3.0.2 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from requests>=2.0.0->requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (3.0.4) Requirement already satisfied: certifi>=2017.4.17 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from requests>=2.0.0->requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (2019.9.11) Requirement already satisfied: urllib3<1.25,>=1.21.1 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from requests>=2.0.0->requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (1.23) Requirement already satisfied: idna<2.8,>=2.5 in ./anaconda3/envs/tensorflow2_p36/lib/python3.6/site-packages (from requests>=2.0.0->requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.1.0,>=2.0.0->tensorflow==2.0.0->-r /home/ubuntu/.dl_binaries/tensorflow2/cpu_3.6/file_with_whl_file_name_for_pip (line 1)) (2.7) Installing collected packages: tensorflow Successfully installed tensorflow-2.0.0 Instance is identified as a CPU instance, removing tensorflow-serving-gpu Installation complete.
サンプルコード mnist_cnn.pyの実行
コードをこちらのページからダウンロードしてきて冒頭で述べたように変更し、実行しました。
このサンプルコードはmnistデータベースという分類問題によく使われる手書き文字を、CNNという畳込み計算とpooling計算とニューラルネットワークを組み合わせたもので分類するものです。
実行結果を折りたたんで貼っておきます。
(tensorflow2_p36) ubuntu@ip-xxx-xx-xx-xx:~$ python mnist_cnn.py Using TensorFlow backend. Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz 11493376/11490434 [==============================] - 2s 0us/step x_train shape: (60000, 28, 28, 1) 60000 train samples 10000 test samples 2020-01-09 04:11:59.478525: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2900060000 Hz 2020-01-09 04:11:59.478738: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x56038e024010 executing computations on platform Host. Devices: 2020-01-09 04:11:59.478870: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): Host, Default Version 2020-01-09 04:11:59.479176: I tensorflow/core/common_runtime/process_util.cc:115] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance. Train on 60000 samples, validate on 10000 samples Epoch 1/12 60000/60000 [==============================] - 94s 2ms/step - loss: 0.2703 - accuracy: 0.9169 - val_loss: 0.0619 - val_accuracy: 0.9795 Epoch 2/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0909 - accuracy: 0.9731 - val_loss: 0.0422 - val_accuracy: 0.9859 Epoch 3/12 60000/60000 [==============================] - 92s 2ms/step - loss: 0.0659 - accuracy: 0.9807 - val_loss: 0.0363 - val_accuracy: 0.9879 Epoch 4/12 60000/60000 [==============================] - 92s 2ms/step - loss: 0.0551 - accuracy: 0.9834 - val_loss: 0.0304 - val_accuracy: 0.9896 Epoch 5/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0470 - accuracy: 0.9861 - val_loss: 0.0276 - val_accuracy: 0.9905 Epoch 6/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0414 - accuracy: 0.9874 - val_loss: 0.0277 - val_accuracy: 0.9916 Epoch 7/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0369 - accuracy: 0.9885 - val_loss: 0.0280 - val_accuracy: 0.9908 Epoch 8/12 60000/60000 [==============================] - 90s 2ms/step - loss: 0.0329 - accuracy: 0.9901 - val_loss: 0.0277 - val_accuracy: 0.9913 Epoch 9/12 60000/60000 [==============================] - 90s 2ms/step - loss: 0.0325 - accuracy: 0.9900 - val_loss: 0.0264 - val_accuracy: 0.9917 Epoch 10/12 60000/60000 [==============================] - 90s 2ms/step - loss: 0.0299 - accuracy: 0.9908 - val_loss: 0.0276 - val_accuracy: 0.9905 Epoch 11/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0277 - accuracy: 0.9915 - val_loss: 0.0261 - val_accuracy: 0.9917 Epoch 12/12 60000/60000 [==============================] - 91s 2ms/step - loss: 0.0263 - accuracy: 0.9919 - val_loss: 0.0264 - val_accuracy: 0.9915 Test loss: 0.026379871594046925 Test accuracy: 0.9915000200271606 経過時間1:1102.439352273941
Gets to 99.25% test accuracy after 12 epochs とサンプルコードにあるとおり、だいたい同じ結果がでました。
そして、試しにライブラリのimportの後からプログラム終了までの時間をiMac (21.5-inch, Late 2015)との比較もしたところ…
| Maschine | run time[sec] |
|---|---|
| iMac (21.5-inch, Late 2015) | 712.4355142116547 |
| c4.large | 1102.43935227394 |
というc4.largeのほうが実行速度が遅いという結果に…
この様に実行速度に差が出た理由としては、単純にCPUの苦手なCNNをさせたことにより、CPUのスペック差が出たためと考えられる。
おわりに
今回、初めてきちんとDeepLearningAMIを使ったが、いつもどおりの方法でEC2インスタンスを建てて、その上で自分に必要な環境をactivateするだけで機械学習の環境構築が済んでしまうため、非常に楽でした。
自分でGPUの型番に合わせて、CUDAなどをインストールして設定するのはなかなかに骨なので。
気をつける点があるとしたら、仮想環境をactivateした際、インスタンスへの最適化をしながらライブラリ等がインストールされるので、その間は待つ必要があることです。