この記事は「スパムFAXを画像解析+言語解析+機械学習でブロックしてみた」の全6回のシリーズ記事の第5回です。
はじめに
前回の記事では【第4回】機械学習前にデータ成形をしてみたを紹介しました。 機械学習のお話です。
大まかな流れ
今回はtext分類ということで、計算コストも深層学習ほど高くなく、良い成果を出せるTf-idf+ロジスティック回帰で実装しています。 ライブラリとしてscikit learnを使用しました。
Tf-idf
Tf-idfは、特定の文書にしか出てこない単語は重要度の高い単語である、という考え方のもと単語をベクトル化する手法です。 この計算はscikit learnのsklearn.feature_extraction.text.TfidfVectorizerで実装されています。基本対応が英語なので前回の前処理では単語をスペースで結合しておきました。
from sklearn.feature_extraction.text import TfidfVectorizer text = ["今日 は 良い 天気 だ","明日 も 良い 天気 だ","明後日 は 良く ない"] vec = TfidfVectorizer().fit_transform(text).toarray() #疎行列から行列に変換 print(vec) -> [[0. 0.68091856 0.51785612 0. 0. 0.51785612 0. ] [0. 0. 0.51785612 0. 0.68091856 0.51785612 0. ] [0.57735027 0. 0. 0.57735027 0. 0. 0.57735027]]
このようなベクトルに変換してくれます。 今回、Faxのテキストでは約2000次元のベクトルになりました。
ロジスティック回帰
ロジスティック回帰は、回帰という名前がついているがクラス分類に使用される一般化線形モデルである。高次元の場合の線形クラス分類は強力であると言われていて、今回は2000次元と高次元のため有効だと判断しました。(SVCだと精度低かった) これもTfidfVectorizerと同じようにscikit learnのsklearn.linear_model.LogisticRegrission実装されています。
Tfidf+ロジスティック回帰で訓練データ40ずつ、テストデータ20ずつで識別してみました。 結果、推測精度は96%までいき、誤識別したのは一つだけでした。これはなかなかいい精度なのでは!?!?
グリッドサーチ
パラメータチュー二ングのためGridSearchCVを用いました。 GridSearchCVは渡されたパラメータをすべての組み合わせで試して、最良のパラメータを出す手法です。 またscikit learnのGradSearchCVでは交差検証も同時に行います。 交差検証とは、訓練データをさらに20%ずつの5つに分け、1つを検証、その他を訓練データとして学習。次は違う1つを検証データとして学習する、これを全組み合わせで行うものです。これを行うことで訓練データをまんべんなく使うことができます。
本当にみてほしいところをみてるのか
よくわからんけどなんかできたではなんの意味もありません。
そのために解析を行いました!
今回はロジスティック回帰の重みパラメータから解析を行います。
scikit learnのロジスティック回帰には.coef_で重みパラメータを取得することができます。
重みパラメータを取得して、それをソートしたものと対応する単語を見ていきたいと思います。
最初にスパムに分類されやすい単語から!
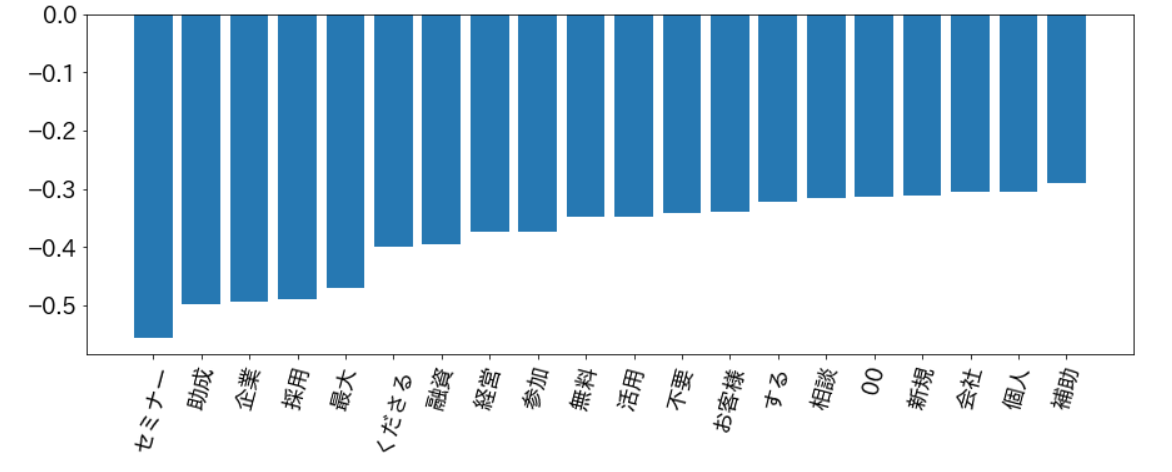
見てわかる通り、必要なさそうな「セミナー」や「採用」などの単語を上手く弾くことができています。
これはなかなかよいのでは!?!?!
次はスパムと判定されづらい単語です。
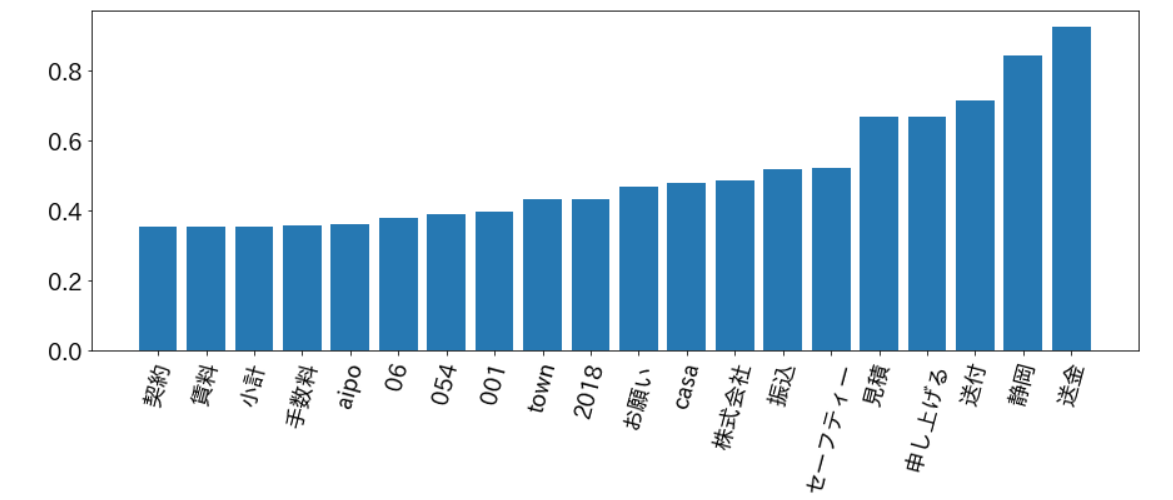
重要そうな「送金」や会社名、自社のアプリケーション、支社がある「静岡」などよく学習できていることがわかります!
次にTfidfの解析です。下の図はTfidf変換後のベクトルを大きい順に並べたものになってます
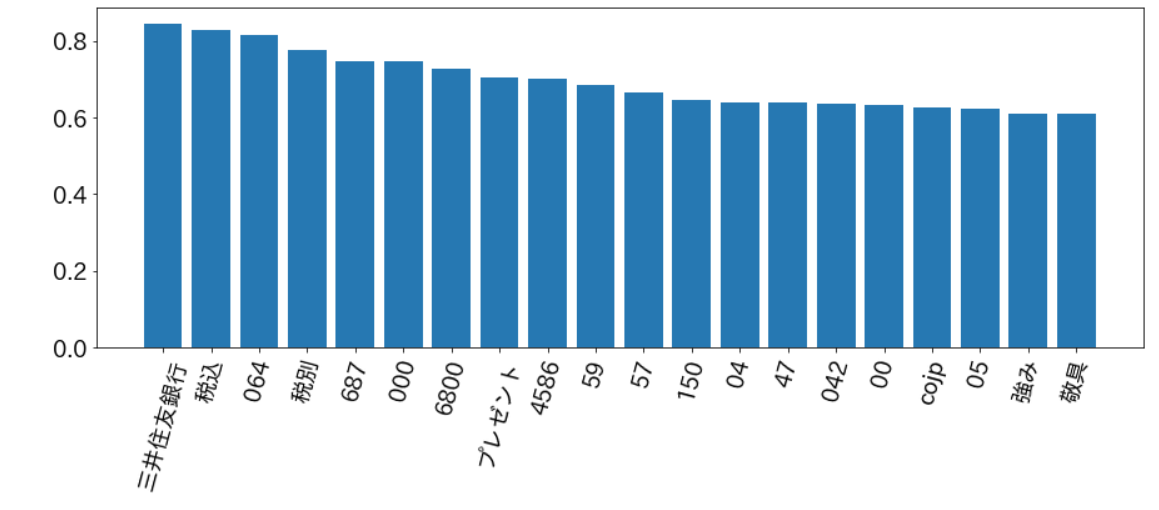
全く関係ない、、、、、、
やっぱり数字は除去したがいいかもしれません(次元数も減るしなんでしてないの僕)
今回は文字認識(OCR)が完璧ではないことからこんな感じでTfidfの効果が出なかったと考察できます。
Tfidfが全く関係ないことを考えると、Bag of wordsの方が良かったかもしれません。
機械学習まとめ
修正点があるにも関わらず、年末から年始にかけて試運転してみたところ、新しいデータは7つあり精度は100%でした(自慢)
ここまでうまく言ったのはスパムとノンスパムの違いがはっきりしているからだと思われます。
機械学習には様々な手法があるため色々悩むよりはやって見て、その結果を分析して次にいくってやり方がいいのかもしれない、、まだ頑張ろう!
ただデータが少ないため日々の新しいデータを学習用のデータにしていく必要があります。
次回では新しいデータを正しいラベルとともに、訓練データにする処理について書いていきます。
おわりに
次回は【第6回】スパム分類失敗をシステムに教えてみたをしていきたいと思います。